Table of Contents
1. Executive Summary
This report was commissioned by DataStax.
Determining the optimal vector solution from the myriad of vector storage and search alternatives that have surfaced is a critical decision with high leverage for an organization. Vectors and AI will be used to build the next generation of intelligent applications for the enterprise and software industry but the most effective option will often also exhibit the highest level of performance.
The benchmark aims to demonstrate the performance of DataStax Astra DB Serverless (Vector) compared to the Pinecone vector database within the burgeoning vector search/database sector. This report contains comprehensive detail on our benchmark and an analysis of the results.
We tested the critical dimensions of vector database performance—throughput, latency, F1 recall/relevance, and TCO. Among the findings that Astra DB produced versus Pinecone:
- 55% to 80% lower TCO
- Up to 6x faster indexing of data
- Up to 9x faster ingestion and indexing of data
We tested throughput, which involved generating vectors and labels, inserting them into databases, and executing queries to measure performance. The queries were of various types, such as nearest neighbor, range, KNN classification, KNN regression, and vector clustering. We also performed latency testing, which measured the response time for each query. Finally, F1 recall/relevance testing measured the database’s performance in returning relevant results for a given query.
The study found that Astra DB significantly outperformed Pinecone p2x8 in ingesting and indexing data, performing six times faster and with a low relative variance, making the ingest workflow more predictable. Astra DB also showed faster response times during active indexing and produced recall ranging from 90% to 94% versus Pinecone’s recall in the range of 75% to 87%. For larger datasets, Astra DB showed better recall and low variance, demonstrating accuracy and consistency. Finally, our testing and configuration pricing revealed that Pinecone’s TCO was 2.2 to 4.9 times greater than Astra DB, making it significantly more expensive to operate.
The results of these tests indicate that DataStax Astra DB Serverless (Vector) is a great choice for storing and searching vectors efficiently.
2. Platform Summary
The concept behind vector databases and their ability to handle unstructured data is relatively simple. Assume your company possesses an extensive collection of textual documents. You want to develop a chatbot capable of responding to inquiries that pertain to the specified documents; however, you do not want the chatbot to have to read every document to do so.
Storing documents in a vector database is optimal for this and numerous other types of applications, where data is stored as high-dimensional vectors, mathematical representations of the features or attributes of an object.
Vector databases are designed to efficiently store and search high-dimensional data. They use graph embeddings, which are low-level representations of items, created using machine learning algorithms. Embeddings are ideal for fuzzy match problems and work with a variety of algorithms. Items that are near each other in this embedding space are considered similar to each other in the real world. Vector databases need to be scalable, performant, and versatile, and they are increasingly popular for a variety of applications involving similarity and generative AI.
Many databases are also adding vector search functionality to their data cloud platform.
DataStax Astra DB Serverless (Vector)
Astra DB is a cloud-native, scalable database-as-a-service (DBaaS) built on Apache Cassandra®, the immensely popular open-source, distributed, wide-column NoSQL database management system. Astra DB eliminates the operational overhead of managing Cassandra clusters, allowing developers to focus on building and deploying their applications. It is fully managed, serverless, and now has vector support. Astra DB also provides high levels of adherence to security and compliance frameworks, including HIPAA, ISO 27001, PCI DSS, and SOC2 Type II.
Vector search is a revolutionary new feature that empowers Astra DB with enhanced search and retrieval functionalities for generative AI applications. This feature allows users to search for specific patterns or concepts within large datasets, enabling faster and more accurate results. With vector search, Astra DB can effectively handle complex queries and provide meaningful insights for various industries such as e-commerce, healthcare, and finance.
Pinecone Vector Database
The Pinecone vector database makes it easy to build high-performance vector search applications. It is developer-friendly, fully managed, and easily scalable without infrastructure hassles and has emerged as an early thought and market share leader in the sector.
With its user-friendly interface, the Pinecone vector database simplifies the process of creating efficient vector search applications. Its managed nature eliminates the need for developers to worry about infrastructure management, allowing them to focus solely on building their applications.
We put these products to the test, selecting tests that have high applicability to most of the needs of a vector database today and for the foreseeable future.
3. Test Setup
The setup for this field test was informed by our field experience in the emerging vector search market. The queries were executed using the following setup, environment, standards, and configurations.
Testing Data and Sizes
Table 1 shows the industry-standard vector datasets we used for testing.
Table 1. Vector Datasets
| Dataset | # of Dimensions | # of Vectors |
|---|---|---|
| GloVe 25 | 25 | 1,183,514 |
| GloVe 50 | 50 | 1,183,514 |
| Last.fm | 65 | 292,385 |
| DEEP1B | 96 | 9,990,000 |
| GloVe 100 | 100 | 1,183,514 |
| GloVe 200 | 200 | 1,183,514 |
| E5 Multilingual | 384 | 100,000 |
| E5 Small | 384 | 100,000 |
| Vertex AI Gecko | 768 | 100,000 |
| E5 Base | 768 | 100,000 |
| E5 Large | 1,024 | 100,000 |
| OpenAI Ada-002 | 1,536 | 100,000 |
| Source: GigaOm 2023 | ||
Testing Harness and Workloads
For our field test, we used NoSQLBench v5.17. This NoSQL and vector database performance testing tool emulates real application workloads. This meant we could perform our model training, indexing, and search performance testing without writing our own testing harness. For those interested in repeating our testing, NoSQLBench v5 (NB5) is an open-source project freely available on GitHub. With NB5, workloads are specified by YAML files.
We had two workloads: liveness and relevancy. Liveness is defined as creating an empty table and storage-attached index (SAI) on Astra DB and an empty pod on Pinecone, loading and ingesting one of the previously defined data sets, and immediately following up with a battery of search queries. Each system does indexing on its own terms. Thus, the indexing state immediately after ingesting is what we are testing. The relevancy test simply repeats the search query battery after the data is fully loaded and indexed.
For Astra DB, the liveness workload executed similar Cassandra Query Language (CQL) to the following:
- Drop any existing table:
DROP INDEX IF EXISTS keyspace_name.index_name; DROP TABLE IF EXISTS keyspace_name.table_name;
- Create a new table_name and SAI index:
CREATE TABLE IF NOT EXISTS keyspace_name.table_name(key TEXT PRIMARY KEY, value VECTOR(FLOAT,<dimension>);
CREATE CUSTOM INDEX IF NOT EXISTS index_name ON keyspace_name.table_name (value) USING 'StorageAttachedIndex') WITH OPTIONS = {'similarity_function': 'cosine'};
- Index the dataset:
INSERT INTO keyspace_name.table_name (key, value) VALUES (...,...);
- Search the vectors:
SELECT * FROM keyspace_name.table_name ORDER BY value ANN OF ... LIMIT 100;
For Pinecone, the approach is similar, except we used their API:
- Drop any existing index:
CURL -X DELETE /databases/index
- Create a new table and SAI index:
CURL -X POST /databases
- Index the dataset:
index.upsert([...])
- Search the vectors:
index.query(vector=[...], top_k=100, include_values=True, include_metadata=True)
Testing Environments
Our benchmark included the following testing environments:
- NoSQLBench
- Cloud: GCP
- Region: us-east1
- SKU: n2-highmem-48
- OS: Ubuntu 20.04.6 LTS (Focal Fossa)
- NB5: 5.17.7
- Astra DB
- Cloud: GCP
- Region: us-east1
- SKU: Serverless
- Pinecone
- Cloud: GCP
- Region: us-east1
- SKU: P2x8
- Replicas: 1
We performed spot testing of multiple replicas on Pinecone. According to Pinecone, increasing the number of replicas provides more throughput and greater availability. Therefore, we tested several datasets at multiple replica counts to see how much our maximum throughput (without errors) could be improved by adding additional replicas. The following chart details the results of those preliminary tests.
Figure 1. Pinecone Max Throughput by Number of Replicas (OPS)
With Pinecone, you pay the same amount for a replica as you do for the primary pod. Thus, a pod with replicas=2 would cost twice as much. So, to achieve desirable price-performance, the throughput would need to double to make the increase in replica costs worth the extra expense. As you can see in Figure 1, three of the datasets in our spot testing produced improved performance when increasing replicas to two, with GloVe 25 and DEEP1B each producing gains greater than 67%. Surprisingly, maximum throughput for the three datasets decreased at replica counts of four and eight.
Of course, replicas should also be considered to improve availability, but for performance testing, we simply wanted to give Pinecone the best possible performance at the lowest possible price. Thus, we used a replica count of one for our field test results presented in the next section. For the total cost of ownership calculations, we used a replica count of two but only to reflect availability requirements.
4. Performance Test Results
The following section details the results of our performance testing using the methods and configurations detailed above. We took many measurements during our testing, but the most relevant and revealing are:
- Ingest and indexing performance
- Search performance (99th percentile response times) during and after indexing
- Recall (accuracy) during and after indexing
We believe measuring performance and recall during indexing is important because while the adoption of vector processing is evolving, there are already strong cases for the ability to index and search in as close to real-time as possible. There is a need to ingest new data and query it immediately.
Indexing Performance
One architectural difference between Astra DB and Pinecone that we noticed right away in our testing was that Astra DB ingested and indexed the data for immediate availability. This can enable time- and mission-critical applications like prompt recommendations based on real-time telemetry. This kind of early action is only possible when supported by real-time and live indexing.
Pinecone, on the other hand, would accept our upsert request, but it took some time before the data was fully indexed and made available for searching. This was particularly true on datasets with large numbers of dimensions and vectors. The largest dataset we tested, DEEP1B, with 96 dimensions and nearly 10 million vectors, took over four hours to index on Pinecone, while Astra DB fully ingested and indexed it in 34 minutes. Figure 2 details the indexing rate for the six datasets with the largest number of vectors.
Figure 2. Time to Ingest and Index Data (in Minutes)
Using this information, we calculated the average indexing rate across all these datasets, as shown in Figure 3. Not only did Astra DB ingest and index this data six times faster than Pinecone p2x8, but it also had a very low relative variance (the standard deviation was 6% of the mean) compared to Pinecone (37%), making the ingest workflow and lead times more predictable.
Figure 3. Indexing Rate Across Platforms
Not only does raw ingest and index performance matter, but so does how active indexing affects query performance? If you are actively ingesting vectors, does it impact search times? We explore that next.
Search Performance
We tested search performance during active ingest (liveness phase) and after the data was fully indexed (relevancy phase). The following chart shows some significant distinctions between DataStax Astra DB Serverless (Vector) and Pinecone P2x8.
The chart in Figure 4 shows the 99th percentile of response time from search queries while vectors are being actively indexed. The Figure 5 chart details the 99th percentile response times after the indexing had completed. We sorted the bars by the dataset with the smallest number of dimensions on the left and the largest on the right.
Figure 4. Search Query Response Times at 99th Percentile During Training
Figure 5. Search Query Response Times at 99th Percentile After Training
First, notice the difference in Pinecone’s performance during active indexing and after indexing completed. After indexing, its performance was much better. However, during active indexing, we saw queries come back with response times well over 1 second and up to 15 times slower. Keep in mind that these are simple search queries. It would appear that there is significant resource contention between concurrent indexing and searching operations.
Second, Astra DB has a faster response time across the board–more than six times faster in the OpenAI Ada-002 dataset during indexing, and almost 74 times faster (in the E5 Small dataset) while ingesting and indexing.
Recall (Accuracy)
Of course, the fastest query execution times are irrelevant if the data returned is unreliable and inaccurate, so we also measured recall, precision, and F1 but focused our results on F1. Figure 6 shows the results for Astra DB, and Figure 7 shows the results for Pinecone. In both charts, higher values are better.
Figure 6. Tested F1 Result for Astra DB
Figure 7. Tested F1 Result for Pinecone
In this chart, we compare Astra DB and Pinecone recall during and after indexing the datasets with large numbers of dimensions (384+) but only 100,000 vectors each. However, the orientation of the graph changes. Astra DB is the top chart, and Pinecone is the bottom. Also, the first data point (top_k=100 active) for each line is the recall achieved while the data was actively being ingested and indexed with top_k=100, where top_k is the number of the top most relevant results (100 in our case) for the query based on the provided vector. The remaining data points are recall values after indexing was completed, and top_k was reduced from 100 to 1.
The difference between Astra DB and Pinecone is clear. First, note that during active indexing, Pinecone recall ranged from 75% to 87%, while Astra DB landed between 90% to 94%. By the time we reached top_k=1, Pinecone had improved to a range of 91% to 98%, while Astra DB improved to 93% to 99.6%. Also, Pinecone produced several readings below 90%, while Astra DB was ensconced above 90% for the entirety of the tests.
For the larger datasets (200,000 to 10M vectors), we saw even more dramatic effects on recall. Since the data ingest time was much longer for Pinecone, we were able to take more recall measurements with a constant barrage of search queries while vectors continued to be indexed. The results were astonishing, with recall measurements on Pinecone coming back with both high and unacceptably low variance. In the worst case, Pinecone had a recall of 23%. Astra DB’s recall was much better, and its variance was extremely low, showing both accuracy and consistency, even at the earliest stages of active indexing.
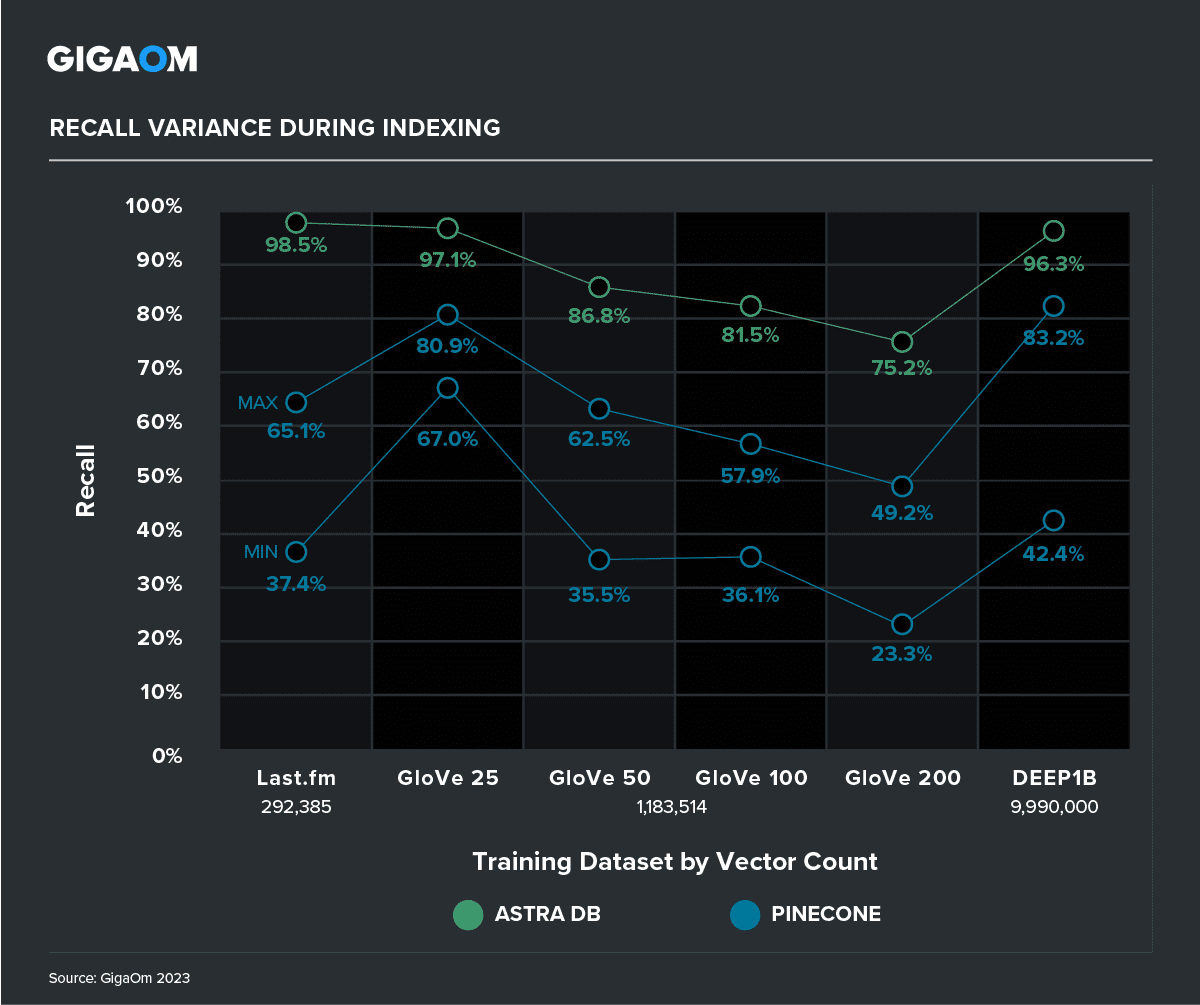 Figure 8. Recall Variance During Indexing
Figure 8. Recall Variance During Indexing
5. Total Cost of Ownership
One significant takeaway from our study thus far is the effect of active ingest and indexing on performance and accuracy in vector database workloads. Consider an enterprise seeking to build a near-real-time search solution for vectorized data, where the latest and most up-to-date information is fed to the application as soon as possible. In this scenario, a chatbot based on RAG (retrieval augmented generation) or FLARE (forward-looking active retrieval) is optimal.
Developed by Facebook AI, RAG is a two-stage approach that first retrieves relevant documents from a large knowledge base and then generates text conditioned on these retrieved documents. This approach leverages the strengths of both retrieval and generation, enabling it to produce more factually accurate and coherent text compared to traditional generation models.
FLARE, developed by Google AI, is a neural network architecture specifically designed for language modeling and generation. It uses a combination of attention and recurrent neural network (RNN) techniques to efficiently process long sequences of text and capture contextual information. This allows FLARE to generate more fluent and natural-sounding text compared to traditional generation models.
Scenarios
We are investigating the TCO scenario for a RAG or FLARE-based chatbot use case. We crafted three scenarios based on the following assumptions:
With any total cost of ownership projection, you have to make numerous assumptions. For our calculations, we used the following constants for our RAG or FLARE-based use case.
- TCO time period: three years
- Dataset Dimensionality: 1,024 dimensions
- Cardinality (new vectors per month): 10,000,000
- Average queries per second: 50 QPS
- Write Size: 5,120 bytes per vector ingested
- Astra DB Storage-Attached Index Size: 5,120 bytes per vector ingested
- Read Size: 51,200 bytes per query
Note that queries per second was a decision we made based on Pinecone’s stated maximum of “up to 200 QPS” with P2 pods. We simply chose 25% of the maximum as a nominal value of average daily usage of 180,000 queries per hour. On our maximum throughput tests of Astra DB, we achieved between 2,000 and 6,000 QPS without errors, depending on the dataset cardinality and dimensionality.
Write and index sizes assume 4 bytes (float type) x 1,024 (vector dimensions) = 4,096 bytes + 1,024 byte non-vector columns = 5,120 bytes per write.
Read size assumes that non-vector column + vector = 1,024 bytes + 4,096 bytes = 5,120 bytes. Then 5,120 bytes per row 100 rows (LIMIT) = 51,200 bytes per read.
Scenario 1: New Dataset Every Month
In this scenario, we consume 10 million new vectors every month. At the beginning of each month, we add the new vectors.
Scenario 2: Continuous New Dataset Every Week
In this scenario, we still consume 10 million new vectors each month, but the new datasets are added weekly to bring the model up-to-date more often.
Scenario 3: Near-Real-Time Data Ingest
In this scenario, we still ingest 10 million new vectors each month, but the data is added as it is received, so it can be leveraged in near-real time.
Administrative Burden Costs
The effect of recall and performance on active indexing is so much that Pinecone would require a continuous improvement and continuous delivery (CI/CD) workflow. With search response times greater than 1 second and recalls under 50%, you would not want to actively index new vectors on your production Pinecone pods. Instead, you would want a new data development workflow to:
- Ingest the new vectors and reindex existing vectors into new pods (pod versioning, if you will).
- Perform quality and assurance (QA) testing to ensure accuracy and performance requirements are met.
- Perform a release cycle (cutover to the new pods).
- Monitor their performance and recall.
- Retain the older version for a predefined amount of time (in case you need to rollback).
We estimate this process would take one business week (five working days) to complete for each data ingestion requiring a scale-up. During this timeframe, two Pinecone environments would run concurrently; the older version of pods running in production and the newer version being indexed, tested, and prepared to replace them.
People’s time and effort costs are more difficult to calculate precisely. They must be estimated, given the varied nature of possible operations and maintenance scenarios, projects, competing priorities, and other factors.
We took inspiration from an agile scrum development project management approach. As experienced consultants, we have extensively used and advocated for the agile project management methodology when developing and operating information management platforms. The agile method is much bigger than the scope of this paper, but for its purposes, we used a few concepts from an agile methodology in this study that may be familiar to readers.
- Story: A story is a specific task that must be completed to develop a new piece of the project or achieve an operational objective.
- Story Size: A story is sized according to how much time and effort is required to complete it. Sizing a story appropriately is an art and a science that requires some experience.
- Story Points: Regardless of the sizing method, the story size is typically expressed as a numeric value to quantify story work and completion.
We used the Fibonacci sequence to quantify size and points, which could be likened to using T-Shirt sizes per the image below. Tasks go from the extra-small (XS) size to the extra-extra-large (XXL) size. Figure 9 shows each size and the corresponding Fibonacci number assigned to it.
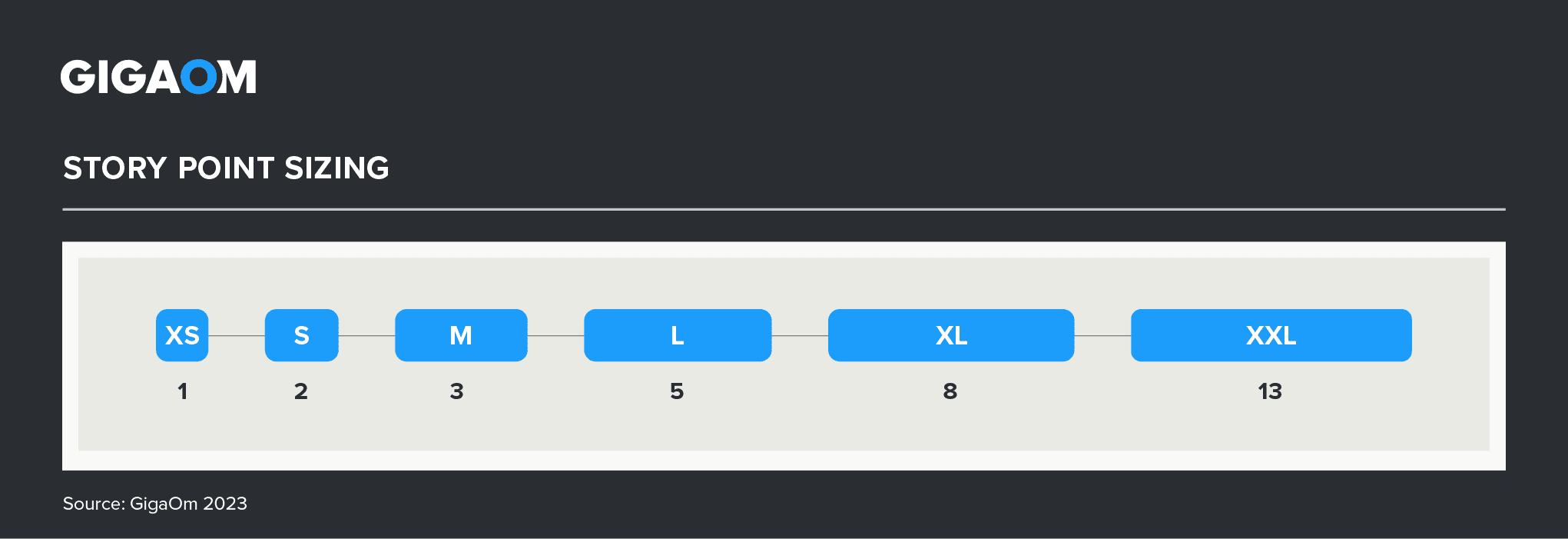
Figure 9. Story Point Scoring Scheme
The tables and graphics that follow show the breakdown of administrative burden, along with the stories and story points. These quantify the differences in managing the two platforms. Table 2 shows the breakdown of stories and story points for Pinecone and DataStax Astra DB Serverless (Vector).
Table 2. Story Point Breakdown
| Story | Pinecone | Astra DB |
|---|---|---|
| INGEST STAGE | 20 | 2 |
| Create new/adapt existing ETL routine | 8 | |
| Index new dataset | 5 | |
| Move dataset into continuous data pipeline | 2 | |
| Re-index existing data | 3 | |
| Size new target indexes | 2 | |
| Stage data | 2 | |
| QA STAGE | 33 | 9 |
| Mitigate errors/issues | 8 | |
| Re-perform post-fix tests | 5 | |
| Perform pre-release unit tests | 3 | 3 |
| Perform pre-release integration tests | 3 | 3 |
| Perform pre-release regression tests | 3 | 3 |
| Perform pre-release performance load tests | 3 | |
| Perform application/functional tests | 5 | |
| Perform pre-release recall tests | 3 | |
| RELEASE STAGE | 26 | 6 |
| Cutover to the new indexes | 3 | |
| Mitigate errors/issues* | 8 | 2 |
| Plan cutover window | 2 | |
| Re-perform post-fix tests* | 5 | 1 |
| Perform weekly functional tests* | 1 | |
| Perform weekly performance load tests* | 1 | |
| Perform weekly recall tests* | 1 | |
| Perform post-release smoke tests | 1 | |
| Perform post-release regression tests | 3 | |
| Perform post-release application tests | 2 | |
| Perform post-release performance tests | 1 | |
| Perform post-release recall tests | 1 | |
| MONITORING STAGE | 3 | 3 |
| Monitor errors | 1 | 1 |
| Monitor performance | 1 | 1 |
| Monitor recall | 1 | 1 |
| RETENTION STAGE | 19 | 0 |
| Backup old indexes | 3 | |
| Drop old indexes | 1 | |
| Plan retention of old indexes | 2 | |
| Rollback (if necessary) | 13 | |
| TOTAL OVERALL STORY POINTS | 101 | 20 |
| Source: GigaOm 2023 | ||
Note that several tasks in the Release Stage section of Table 2 are marked with an asterisk. For Astra DB, these marked tasks are spread over a month, while for Pinecone, they are performed during the shortened five-day release cycle. Thus, Astra DB’s levels of effort (story points) were normalized per week to match.
Our findings: Pinecone required about five times more staff time and effort during cutovers to new datasets over simply adding them in Astra DB. Thus, for our TCO calculations, we used a team of five full-time equivalent (FTE) engineers during periods of new data cutovers on Pinecone (with one full-time engineer for ongoing maintenance), compared to a single FTE data engineer on the DataStax build and maintenance team.
Figure 10 visually depicts the relative density of effort required for each platform, working from the scoring shown in Table 2. Note how Astra DB blocks are both fewer and more compact, meaning not only are there fewer tasks and steps with Astra DB, but the ones that exist are more quickly completed.
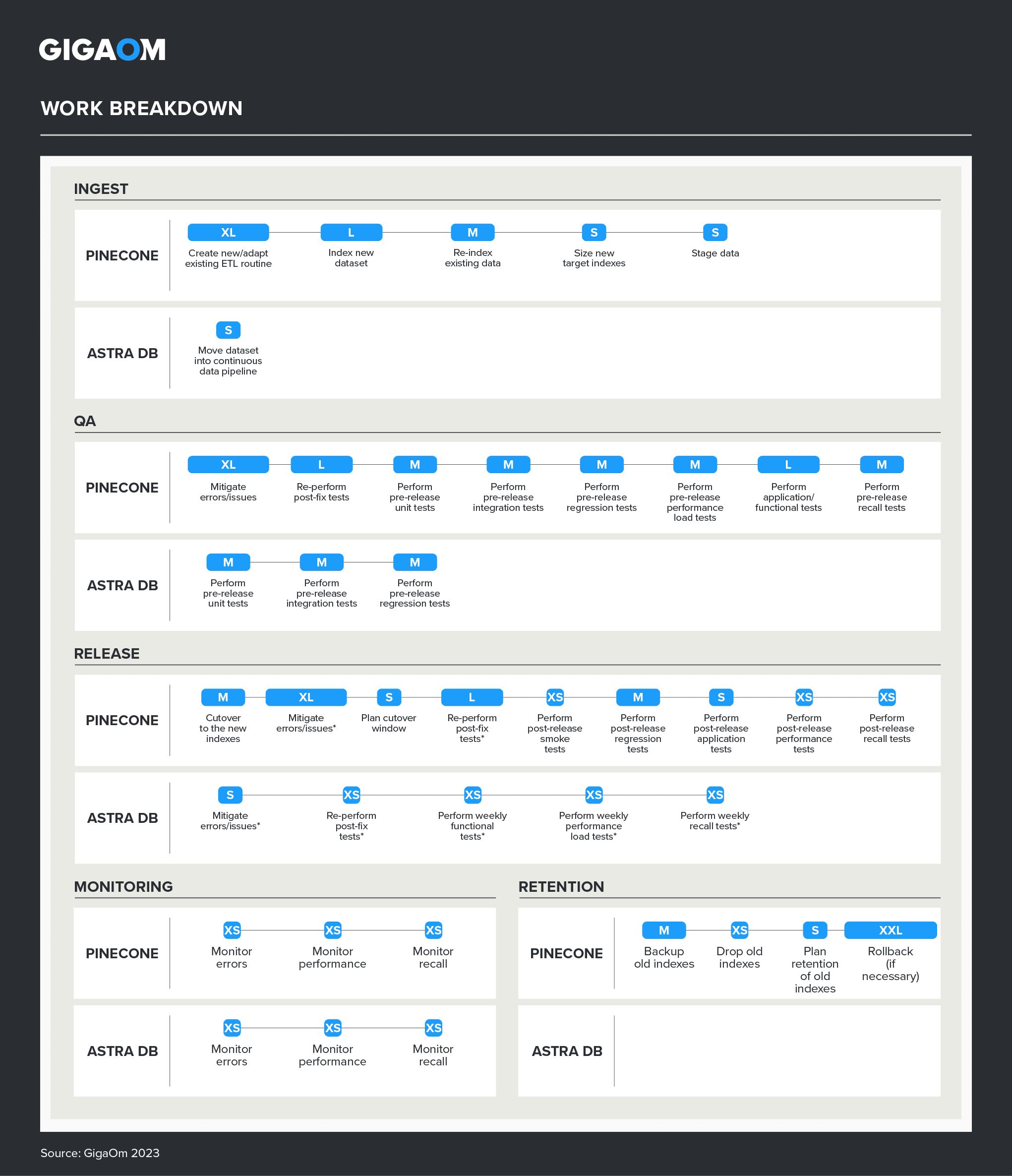
Figure 10. Work Breakdown Showing Number and Intensity of Tasks
Total Cost of Ownership Calculation
To put a dollar amount of people’s time and effort, we used salary and benefits as our basis, as enumerated in Table 3. Vector database administration is an evolving and underrepresented talent that commands more compensation. Our research reveals an average salary for vector database developers is approximately $250,000 per year.
In the case of Astra DB, users would only have to worry about ingest and search performance and accuracy monitoring, freeing up vector data engineers for innovation and development of new capabilities, rather than the care of Astra DB itself.
Table 3. People Costs
| People Costs | Pinecone Data Engineers |
|---|---|
| Average Annual Cash Compensation | $250,000 |
| Benefits Rate | 22% |
| Fully Burdened Annual Labor Cost | $305,000 |
| Standard Work Hours per Year | 2,080 |
| Hourly rate | $147 |
| % Mix of Labor Effort in Production | 100% |
| Labor Cost per Hour | $146.63 |
| Proposed Team Size (Pinecone) | 5 (during cut-over), 1 full-time |
| Proposed Team Size (Astra DB) | 1 full-time |
| Source: GigaOm 2023 | |
DataStax Astra DB Serverless (Vector)
As a serverless DBaaS platform, DataStax implements usage-based pricing, charging users based on volume of reads and writes, data storage, and data transfers, as well as optionally on support. Table 4 breaks down the cost factors. Note that WRU stands for write request units and RRU stands for read request units. These represent kilobytes per read/write.
Table 4. Cost Breakdown
| Cost Breakdown | Unit Cost | Basis | Cost |
|---|---|---|---|
| COMPUTE COSTS | |||
| Table Write Request Units* | $0.61 per 1M | 5 WRU per write | $30.50 |
| Index Write Request Units* | $0.61 per 1M | 5 WRU per write | $30.50 |
| Read Request Units | $0.36 per 1M | 125 RRU per read | $233.28 |
| Vector Dimension Writes | $0.04 per 1M | writes x dimensions | $409.60 |
| Vector Dimension Reads | $0.04 per 1M | reads x dimensions | $5,308.42 |
| Monthly Compute Costs | $6,012 | ||
| 3-Year Compute Costs | $216,443 | ||
| STORAGE COSTS | |||
| Data Storage | $0.25 per 1 GB | +115 GB each month | $12,765 |
| Data Transfer | $0.02 per 1 GB | +231 GB each month | $2,051 |
| SUPPORT COSTS | |||
| Enterprise Support (Optional) | $838.85 | per month | $30,199 |
| COST TOTALS | |||
| 3-Year Total Usage Cost | all scenarios** | $261,458 | |
| 3-Year Administrative Burden (Table 3 People Costs) | $915,000 | ||
| 3-Year Total Cost of Ownership | $1,176,458 | ||
| Source: GigaOm 2023 | |||
Given the Astra DB cost model, the number of new vectors per month (10 million), and the average query rate (50 QPS), costs across all three scenarios should be virtually the same (give or take approximately $1,000 based on storage volume fluctuations based on when new vectors are ingested).
Pinecone
Pinecone charges by pod usage, which includes a fixed amount of compute and storage. According to Pinecone, a p2 pod with 1,024 dimensions will hold about 1M vectors. Thus, a p2x8 should hold about 8M vectors.
- Line item: p2x8 Pod
- Unit cost: $840.96 per replica per month
- Replicas: 2
- Monthly cost: $1,681.92 per pod
Even though Pinecone’s cost model is simpler, the total cost of ownership is complicated and varies considerably on how it scales and how people are allocated to support scaling.
We have now established the assumptions and fixed costs to understand the differences in the TCO between scenarios for Pinecone–the unit cost of using the platform and the administrative burden required to support and scale pods.
To save money on Pinecone, we also made the decision to only retain vectors for one year. This is unnecessary on Astra DB because data storage is so inexpensive.
One of Pinecone’s downsides from a price-performance perspective is that the pods have tightly coupled compute and storage. This can create side effects to the price customers pay when only extra compute or storage is needed but not both. For example, if you need to double your throughput but do not need additional storage, you increase your pods or replicas, but you get and pay for the additional storage whether you need it or not. Likewise, if you simply need additional storage, you have to increase the number of pods (not replicas) and pay for the extra compute power, even if you do not need it.
Second, another issue with Pinecone is that, at the time of writing, pods cannot be scaled once they are created. Thus, you either have to set the number of pods and replicas based on what you anticipate you will need in terms of throughput, storage, and availability, or as we have shown, you must go through a pod migration production cycle to achieve scalability.
Table 5 breaks down the cost of using Pinecone given our three scenarios. Since each p2x8 pod will hold 8 million vectors, every time our dataset exceeds a multiple of 8 million, we triggered a scale-up CI/CD process and increased the total number of pods, figuring the overlap of time when both production and development pods are in use.
Table 5. 3-Year Pinecone Cost Breakdown Across 3 Scenarios
| Scenario | New Dataset Monthly | Continuous New Dataset Weekly | Near Real-Time Data Ingest |
|---|---|---|---|
| Cutover Days per Month | 5 | 25 | Constant |
| PODS NEEDED BY MONTH | |||
| Month 1 | 1 | 2 | 20 |
| Month 2 | 2.17 | 2.67 | 20 |
| Month 3 | 3.33 | 3.67 | 20 |
| Month 4 | 4.5 | 6 | 20 |
| Month 5 | 5.67 | 8 | 20 |
| Month 6 | 7.83 | 9.67 | 20 |
| Month 7 | 9.17 | 12 | 20 |
| Month 8 | 10.5 | 14 | 20 |
| Month 9 | 11.67 | 15.67 | 20 |
| Month 10 | 13.83 | 18 | 20 |
| Month 11 | 15.17 | 20 | 20 |
| Month 12 | 16.5 | 21.67 | 20 |
| COST BREAKDOWN | |||
| Year 1 Total Cost | $170,435 | $224,256 | $403,661 |
| Year 2 Total Cost | $353,203 | $400,297 | $403,661 |
| Year 3 Total Cost | $353,203 | $400,297 | $403,661 |
| 3-Year Total Usage Costs | $876,841 | $1,024,850 | $1,210,982 |
| 3-Year Administrative Burden (People Costs) | $1,759,615 | $4,575,000 | $4,575,000 |
| 3-Year Total Cost of Ownership | $2,636,456 | $5,599,850 | $5,785,982 |
| Source: GigaOm 2023 | |||
Finally, Figure 11 totals up the three-year TCO for Astra DB and each of the Pinecone deployments. The result: Astra DB enjoys a profound cost advantage over Pinecone, with Pinecone producing TCO figures that are 2.2 to 4.9 times greater than that of Astra DB.
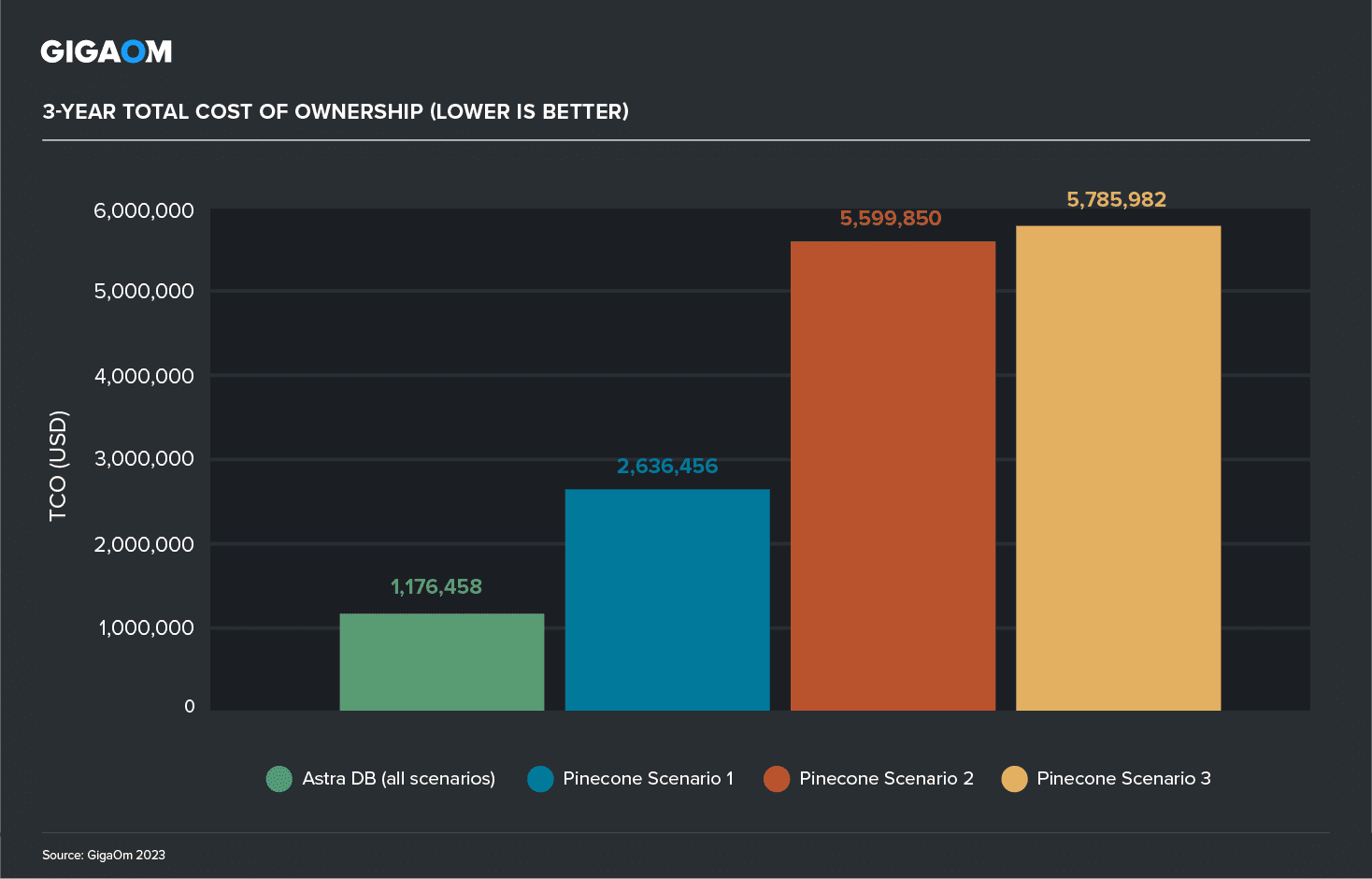
Figure 11. Total Cost of Ownership
6. Conclusion
Identifying the optimal vector solution among the numerous vector storage and searching alternatives that have emerged is critical. This is a high-leverage, crucial decision for an organization. Vectors and artificial intelligence will be utilized in both the enterprise and software sectors to develop the next iteration of intelligent applications. The most effective option frequently demonstrates the highest degree of performance.
We evaluated the performance of DataStax Astra DB Serverless (Vector) and Pinecone in terms of throughput, latency, F1 recall/relevance, and total cost of ownership.
The average indexing rate was computed for each of the datasets. Astra DB exhibited a superior data ingest and indexing speed of six times when compared to Pinecone p2x8. Additionally, Astra DB maintained a remarkably low relative variance of 6% of the mean (versus 37% for Pinecone), which enhanced the predictability of the ingest workflow and lead times.
During active indexing, we observed response times for queries exceeding one second, with Pinecone responding up to 15 times more slowly. The response time of Astra DB is consistently faster, with speeds of up to 74 times quicker during ingesting and indexing and up to six times faster after indexing.
- Pinecone recall ranged from 75% to 87% during active indexing, whereas Astra DB recall ranged from 90% to 94%.
- At top_k=1, Pinecone recall improved to the range of 91% to 98%, while Astra DB improved to a range of 93% to 99.6%.
- In addition, Pinecone recorded multiple readings below 90%, whereas Astra DB remained above 90% throughout the entire battery of tests.
Pinecone experienced a recall rate as low as 23%. Astra DB demonstrated enhanced recall and exceptionally low variance, indicating remarkable accuracy and consistency during the initial phases of active indexing.
In our three scenarios (monthly new datasets, weekly continuous new datasets, and near-real-time data ingestion), Pinecone’s TCO was between 2.2 and 4.9 times that of Astra DB.
DataStax Astra DB Serverless (Vector) is a very compelling option for effectively storing and searching vectors, according to the test results.
7. Disclaimer
Performance is important but is only one criterion for a data warehouse platform selection. This is only one point-in-time check into specific performance. There are numerous other factors to consider in selection across factors of administration, integration, workload management, user interface, scalability, vendor, reliability, and numerous other criteria. It is also our experience that performance changes over time and is competitively different for different workloads. A performance leader can hit up against the point of diminishing returns and viable contenders can quickly close the gap.
GigaOm runs all of its performance tests to strict ethical standards. The results of the report are the objective results of the application of queries to the simulations described in the report. The report clearly defines the selected criteria and process used to establish the field test. The report also clearly states the data set sizes, the platforms, the queries, etc. used. The reader is left to determine for themselves how to qualify the information for their individual needs. The report does not make any claim regarding third-party certification and presents the objective results received from the application of the process to the criteria as described in the report. The report strictly measures performance and does not purport to evaluate other factors that potential customers may find relevant when making a purchase decision.
This is a commissioned report. DataStax chose the competitors, the test, and the DataStax Astra DB Serverless (Vector) configuration. GigaOm chose the most compatible configurations for the other tested platforms and ran the queries. Choosing compatible configurations is subject to judgment. We have attempted to describe our decisions in this paper.
In this writeup, all the information necessary is included to replicate this test. You are encouraged to compile your own representative queries, data sets, data sizes and compatible configurations and test for yourself.
8. About DataStax
DataStax is at the forefront of the generative AI revolution, with proven technologies that empower any organization to deliver the AI-powered applications that are redefining business.
DataStax’s Astra DB, the industry’s only vector database for building real-world, production-level AI applications using real-time data. Built on Apache Cassandra®—the massively scalable open source database proven by AI leaders—Astra DB is the data engine for responsive AI applications that consistently deliver accurate results, without artificial hallucinations.
Thousands of developers and hundreds of the world’s leading enterprises, including Audi, Capital One, The Home Depot, Verizon, VerSe Innovation, and many more rely on DataStax technologies.
9. About William McKnight
William McKnight is a former Fortune 50 technology executive and database engineer. An Ernst & Young Entrepreneur of the Year finalist and frequent best practices judge, he helps enterprise clients with action plans, architectures, strategies, and technology tools to manage information.
Currently, William is an analyst for GigaOm Research who takes corporate information and turns it into a bottom-line-enhancing asset. He has worked with Dong Energy, France Telecom, Pfizer, Samba Bank, ScotiaBank, Teva Pharmaceuticals, and Verizon, among many others. William focuses on delivering business value and solving business problems utilizing proven approaches in information management.
10. About Jake Dolezal
Jake Dolezal is a contributing analyst at GigaOm. He has two decades of experience in the information management field, with expertise in analytics, data warehousing, master data management, data governance, business intelligence, statistics, data modeling and integration, and visualization. Jake has solved technical problems across a broad range of industries, including healthcare, education, government, manufacturing, engineering, hospitality, and restaurants. He has a doctorate in information management from Syracuse University.
11. About GigaOm
GigaOm provides technical, operational, and business advice for IT’s strategic digital enterprise and business initiatives. Enterprise business leaders, CIOs, and technology organizations partner with GigaOm for practical, actionable, strategic, and visionary advice for modernizing and transforming their business. GigaOm’s advice empowers enterprises to successfully compete in an increasingly complicated business atmosphere that requires a solid understanding of constantly changing customer demands.
GigaOm works directly with enterprises both inside and outside of the IT organization to apply proven research and methodologies designed to avoid pitfalls and roadblocks while balancing risk and innovation. Research methodologies include but are not limited to adoption and benchmarking surveys, use cases, interviews, ROI/TCO, market landscapes, strategic trends, and technical benchmarks. Our analysts possess 20+ years of experience advising a spectrum of clients from early adopters to mainstream enterprises.
GigaOm’s perspective is that of the unbiased enterprise practitioner. Through this perspective, GigaOm connects with engaged and loyal subscribers on a deep and meaningful level.
12. Copyright
© Knowingly, Inc. 2023 "Vector Databases Compared" is a trademark of Knowingly, Inc. For permission to reproduce this report, please contact sales@gigaom.com.