First, a story. When I returned to being a software industry analyst in 2015 or thereabouts, I had a fair amount of imposter syndrome. I thought, everyone’s now doing this DevOps thing and all problems are solved! Netflix seemed to have come from nowhere and said, you just need to build these massively distributed systems, and it’s all going to work – you just need a few chaos monkeys.
As a consequence, I spent over a year writing a report about how to scale DevOps in the enterprise. That was the ultimate title, but at its heart was a lot of research into, what don’t I understand? What’s working; and what, if anything, isn’t? It turned out that, alongside the major successes of agile, distributed, cloud-based application delivery, we’d created a monster.
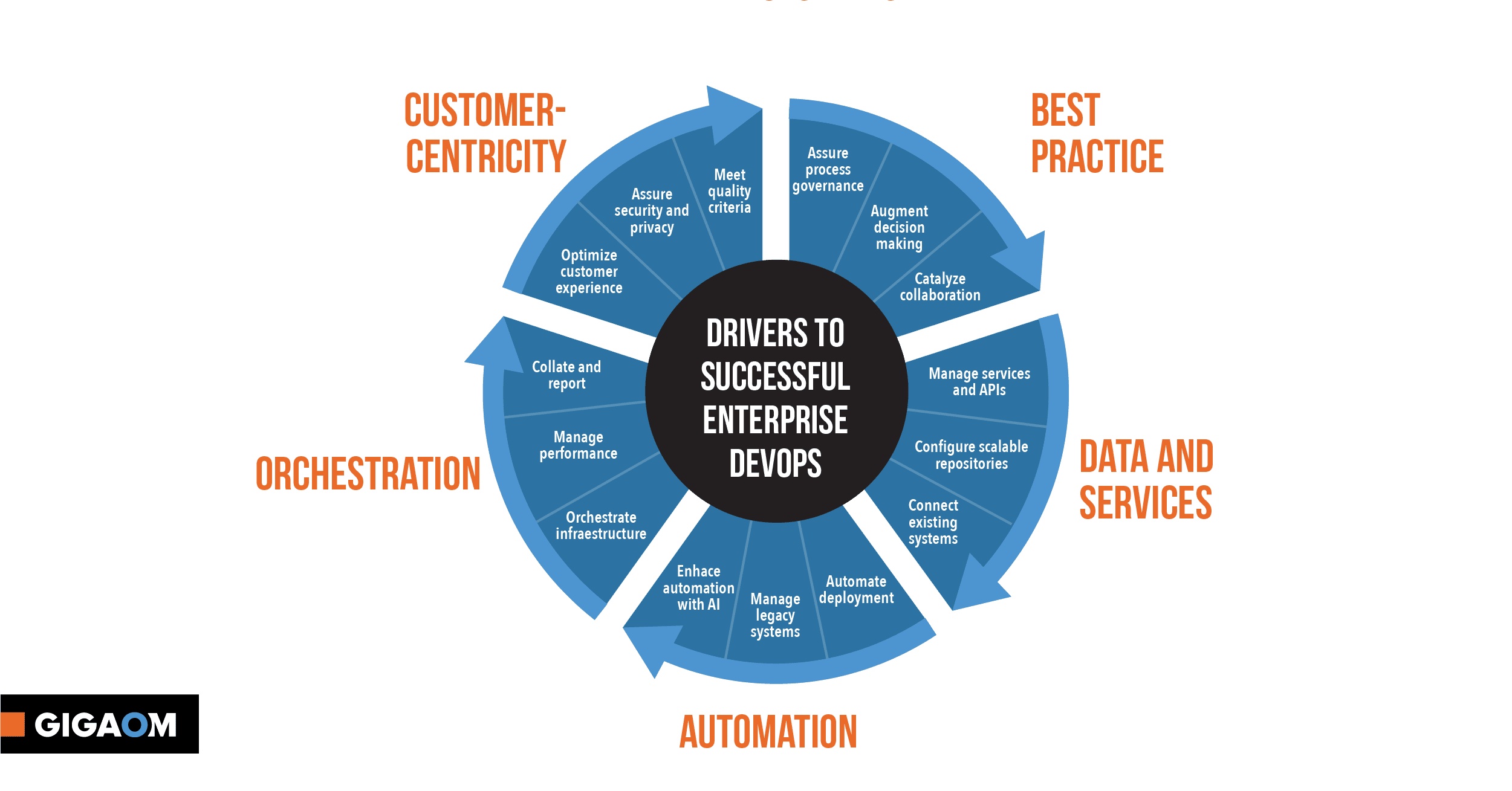
Whilst the report is quite extensive, the missing elements could be summarized as – we now have all the pieces we need to build whatever we want, but there’s no blueprint of how to get there, in process or architecture terms. As a result, best practices have been replaced by frontiership, with end-to-end expertise becoming the domain of specialists.
Since my minor epiphany we’ve seen the rise of microservices, which give us both the generalized principle of modularization and the specific tooling of Kubernetes to orchestrate the resulting, container-based structures. So much of this is great, but once again, there’s no overarching way of doing things. Developers have become like the Keymaster in The Matrix – there are so many options to choose from, but you need a brain the size of a planet to remember where they all are, and pick one.
It’s fair to bring in science fiction comparisons, which tend to be binary – either sleek lines of giant, beautifully constructed spaceships, or massively complex engine rooms, workshops with trailing wires, and half-built structures, never to be completed. We long for the former, but have created the latter, a dystopian dream of hyper-distributed DIY.
But we are, above all, problem solvers. So, we create principles and tools to address the mess we have made—site reliability engineers (SREs) to oversee concept to delivery, shepherding our silicon flocks towards success; and Observability tools to solve the whodunnit challenge that distributed debugging has become. Even DevOps itself, which sets its stall about breaking down the wall of confusion between the two most interested parties, the creators of innovation, and those shovelling up the mess that often results.
The clock is ticking, as the rest of the business is starting to blink. We’re three to four years into much-trumpeted ‘digital transformation’ initiatives, and companies are seeing they don’t quite work. “I thought we could just deploy a product, or lift and shift to the cloud, and we’d be digital,” said one CEO to us. Well, guess what, you’re not.
We see the occasional report that says an organization has gone back to monoliths (AWS among them) or moved applications out of the cloud (such as 37 Signals). Fair enough – for well-specced workloads, it’s more straightforward to define a cost-effective architecture and assess infrastructure costs. For the majority of new deployments, however, even building a picture of the application is hard enough, let alone understanding how much it costs to run, or the spend on a raft of development tools that need to be integrated, kept in sync and otherwise tinkered with.
I apologize in part for the long preamble, but this is where we are, coping with the flotsam of complexity even as we try to show value. Development shops are running into the sand, knowing that it won’t get any easier. But there isn’t a side door you can open, to step out of the complexity. Meanwhile, costs continue to spiral out of control – software-defined sticker shock, if you will. So, what can organizations do?
The playbook, to me, is the same one I have often used when auditing or fixing software projects – start figuratively at the beginning, look for what is missing, and put it back where it should be. Most projects are not all bad: if you’re driving north, you may be heading roughly in the right direction, but stopping off and buying a map might get you there just a little bit quicker. Or indeed, having tools to help you create one.
To whit, Microsoft’s recently announced Radius project. First, let me explain what it is – an architecture definition and orchestration layer that sits above, and works alongside, existing deployment tools. To get your application into production, you might use Terraform to define your infrastructure requirements, Helm charts to describe how your Kubernetes cluster needs to look, or Ansible to deploy and configure an application. Radius works with these tools, pulling together the pieces to enable a complete deployment.
You may well be asking, “But can’t I do that with XYZ deployment tool?” because, yes, there’s a plethora out there. So, what’s so different? First, Radius works at both an infrastructure and an application level; building on this, it brings in the notion of pre-defined, application-level patterns that consider infrastructure. Finally, it is being released as open source, making the tool, its integrations, and resulting patterns more broadly available.
As so often with software tooling, the impetus for Radius has come from within an organization – in this case, from software architect Ryan Nowak, in Microsoft’s incubations group. “I’m mostly interested in best practices, how people write code. What makes them successful? What kind of patterns they like to use and what kind of tools they like to use?” he says. This is important – whilst Radius’ mechanism may be orchestration, the goal is to help developers develop, without getting bogged down in infrastructure.
So, for example, Radius is Infrastructure as Code (IaC) language independent. The core language for its ‘recipes’ (I know, Chef uses the same term) is Microsoft’s Bicep, but it supports any orchestration language, naturally including the list above. As an orchestrator working at the architectural level, it enables a view of what makes up an application – not just the IaC elements, but also the API configurations, key-value store and other data.
Radius then also enables you to create an application architecture graph – you know what the application looks like because you (or your infrastructure experts) defined it that way in advance, rather than trying to work it out in hindsight from its individual atomic elements like observability tools try to do. The latter is laudable, but how about, you know, starting with a clear picture rather than having to build one? Crazy, right?
As an ex-unified modeling language (UML) consultant, the notion of starting with a graph-like picture inevitably makes me smile. While I’m not wed to model-driven design, the key was that models bring their own guardrails. You can set out what can communicate with what, for example. You can look at a picture and see any imbalances more easily than a bunch of text, such as monolithic containers, versus ones that are too granular or have significant levels of interdependency.
Back in the day, we also used to separate analysis, design, and deployment. Analysis would look at the problem space and create a loose set of constructs; design would map these onto workable technical capabilities; and deployment would shift the results into a live environment. In these software-defined days, we’ve done away with such barriers – everything is code, and everyone is responsible for it. All is well and good, but this has created new challenges that Radius looks to address.
Not least, by bringing in the principle of a catalog of deployment patterns, Radius creates a separation of concerns between development and operations. This is a contentious area (see above about walls of confusion), but the key is in the word ‘catalog’ – developers gain self-service access to a library of infrastructure options. They are still deploying to the infrastructure they specify, but it is pre-tested and secure, with all the bells and whistles (firewall configuration, diagnostics, management tooling and so on), plus best practice guidance for how to use it.
The other separation of concerns is between what end-user organizations need to do and what the market needs to provide. The idea of a library of pre-built architectural constructs is not new, but if it happens today, it will be an internal project maintained by engineers or contractors. Software-based innovation is hard, as is understanding cloud-based deployment options. I would argue that organizations should focus on these two areas, and not on maintaining the tools to support them.
Nonetheless, and let’s get the standard phrase out of the way – Radius is not a magic bullet. It won’t ‘solve’ cloud complexity or prevent poor decisions from leading to over-expensive deployments, under-utilized applications, or disappointing user experiences. What it does, however, is get responsibility and repeatability into the mix at the right level. It shifts infrastructure governance to the level of application architecture, and that is to be welcomed.
Used in the right way (that is, without attempting to architect every possibility ad absurdum), Radius should reduce costs and make for more efficient delivery. New doors open, for example, to making more multi-cloud resources with a consistent set of tools, and increasing flexibility around where applications are deployed. Costs can become more visible and predictable up front, based on prior experience of using the same recipes (it would be good to see a FinOps element in there).
As a result, developers can indeed get on with being developers, and infrastructure engineers can get on with being that. Platform engineers and SREs become the curators of a library of infrastructure resources, creating wheels rather than reinventing them and bundling policy-driven guidance their teams need to deliver innovative new software.
Radius may still be nascent – first announced in October, it is planned for submission to the cloud native computing foundation (CNCF); it is currently Kubernetes-only, though given its architecture-level approach, this does not need to be a limitation. There may be other, similar tools in the making; Terramate stacks deserve a look-see, for example. But with its focus on architecture-level challenges, Radius sets a direction and creates a welcome piece of kit in the bag for organizations looking to get on top of the software-defined maelstrom we have managed to create.